Dịch vụ chuẩn bị dữ liệu AI
Ngày: 30/10/2020
Về cơ bản các bước để giải quyết một bài toán Deep Learning trong Computer Vision gồm:
1. Thu thập dữ liệu cho bài toán.
2. Đánh nhãn dữ liệu thu thập được.
3. Chọn các mô hình Deep Learning phù hợp với bài toán, tiến hành huấn luyện, kiểm thử và đánh giá.
4. Lặp lại các bước trên cho đến khi thỏa mãn yêu cầu của bài toán.
Đa số chúng ta đều quan tâm đến bước số 3 của bài toán là bước chọn các mô hình và các phương pháp cải thiện model hyperparameters nhằm đạt được error rate thấp nhất, cho ra kết quả chính xác nhất.
Hai bước đầu tưởng chừng khá đơn giản nhưng lại vô cùng quan trọng mà chúng ta thường bỏ qua.
- Bước thu thập dữ liệu để huấn luyện cho mô hình: các mô hình Deep Learning không thể hoạt động nếu thiếu dữ liệu, trường hợp bộ dữ liệu quá nhỏ thì dễ dẫn đến overfiting và mô hình không thể học được đầy đủ các tính năng cho các trường hợp tổng quan.
- Đánh nhãn dữ liệu sẽ đánh giá mô hình chúng ta làm việc tốt hay không. Đánh nhãn sai dữ liệu sẽ làm cho mô hình dự đoán và đánh giá sai, tốn nhiều thời gian và công sức bỏ ra cho quá trình huấn luyện.
Vậy làm sao để tìm "đủ" dữ liệu huấn luyện và đánh nhãn cho nó? Làm thế nào để đánh nhãn dữ liệu? Và ai sẽ đánh nhãn dữ liệu? Có thể nói đây là quá trình tốn nhiều thời gian và công sức nhất của Deep Learning trong Computer Vision.
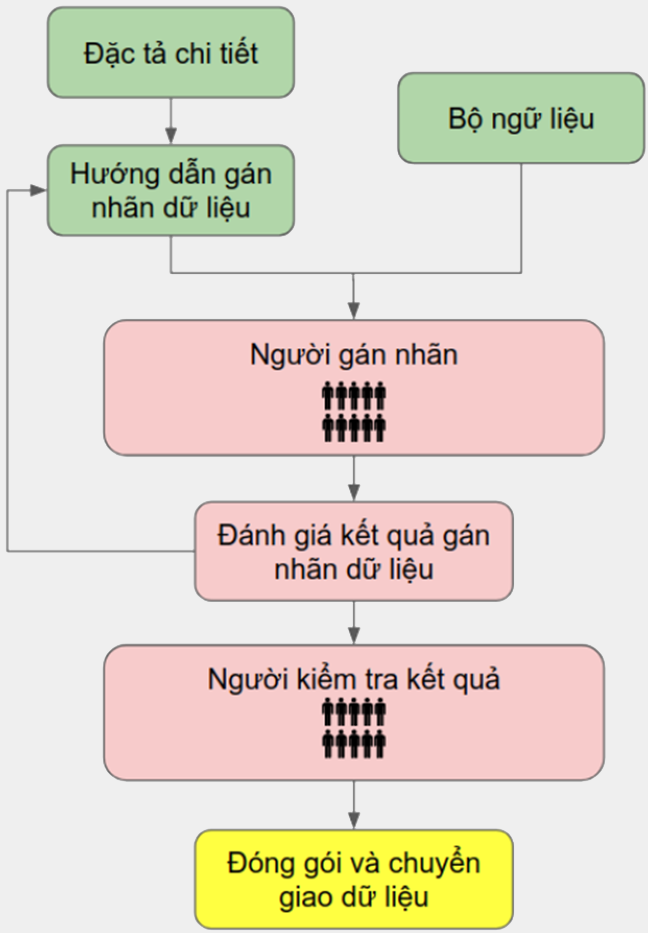
Quy trình đánh nhãn dữ liệu
AVA cung cấp dịch vụ chuẩn bị dữ liệu AI hỗ trợ khách hàng giải quyết nhanh và chính xác bài toán thu thập và đánh nhãn dữ liệu.
